Heiner Kücker
Semantisches Netz
Java-Seite
Alaska-XBase++-Seite
Projekte
Philosophien
Techniken
Konzepte
Artikelsystematik
Semantisches_Netz
Flexible_Columns
Weiterentwicklung_Java
Fehlerquellen
Längencodierung
Encoding
Programming_by_Contract
TimelineStructure
Datenstruktur für
Kalender oder
Terminplaner
Sudoku
Kontakt /
Impressum
Links
SiteMap
Letzte Aktualisierung:
09.01.2003
Semantisches Netz
Ein semantisches Netz ist eine Lösung zur Datenmodellierung, die wesentlich flexibler als das klassische Entity-Relationship-Modell ist. Es basiert auf den Konzepten der Sprache Prolog.Zum Erweitern des Datenmodells sind keine Strukturänderungen nötig.
Das Netz besteht aus Knoten und ihren Verknüpfungen.
Zwei Konoten und ihre Verknüpfung bilden jeweils eine Ausage.
Aussagesatz:
Knoten | Verknüpfung | Knoten
Subjekt | Prädikat | Objekt

Da Subjekt und Objekt vertauschbar sind (in einer natürlichen Sprache durch Passivform des Prädikats) wird in diesem Modell nicht nach Subjekt und Objekt unterschieden.
Hier ein Beispiel für ein für ein semantisches Netz:
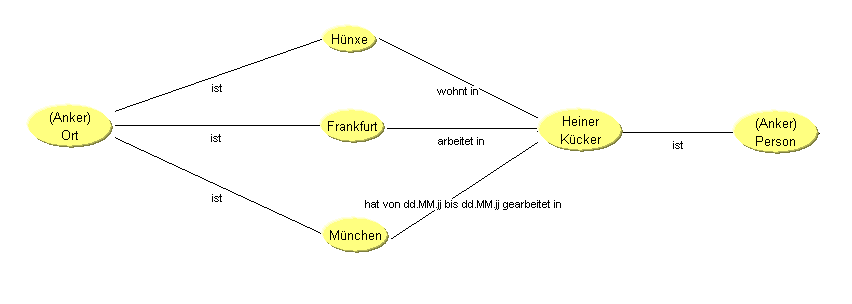
Beim Prädikat "ist" handelt es sich um eine besondere Verknüpfung, um eine Elementarverknüpfung.
An dem Prädikat "hat von dd.MM.jjjj bis dd.MM.jjjj gearbeitet in" sieht man, daß es möglich sein sollte, Prädikate mit Attributen zu versehen.
Jedes Attribut muß einen Namen, einen Datentyp und einen Wert besitzen.
Dementsprechend sind auch Attribute für die Knoten notwendig.
Außerdem gibt es spezielle Knoten, die Anker.
Die Anker dienen als Eingänge in das semantische Netz.
Um praktisch mit dem semantischen Netz arbeiten zu können gibt es verschiedene Views:
Form View
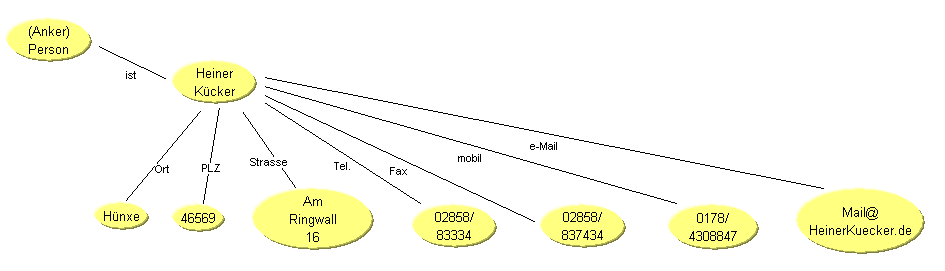
Für ein FormView ist ein Anker und ein bestimmter daran angebundener Knoten erforderlich.
Für diesen Knoten können nun die entsprechenden Prädikate editiert werden.
Anker >> Knoten >> Verknüpfung >> Formularfeld (Knoten)
Eine Besonderheit ist das Prädikat Ort. Da Ort selbst ein Ankerelement ist, muß hier eigentlich eine Selectbox zum Editieren verwendet werden.
Table View
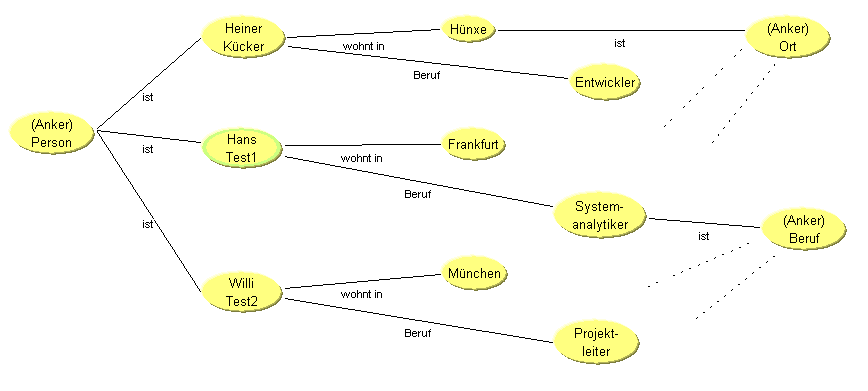
| Table: Person | ||
|---|---|---|
| ist | wohnt in | Beruf |
| Heiner Kücker | Entwickler | Hünxe |
| Hans Test1 | Frankfurt | Systemanalytiker |
| Hans Test2 | München | Projektleiter |
Für eine TableView benötigt man einen Anker.
Jedes mit dem Anker verbundene Element (Ankerelement) erzeugt eine Tabellenzeile.
Für weitere Tabellenspalten müssen jeweils weitere Prädikate herangezogen werden.
Tree View
Ausgehend von einem Anker gesehen, ist das semantische Netz immer ein Baum.Man kann sagen, daß das semantische Netz eine Verallgemeinerung des Baum-Modells ist.
Auf eine spezielle Abbildung verzichte ich hier.
Operationen im semantischen Netz
Prinzipiell muß die Möglichkeit bestehen Konten, Prädikate und Aussagen Anzulegen(Setzen), zu Ändern und zu Löschen.Eine Besonderheit stellen die Ankerknoten dar.
Beim Ändern oder Löschen müssen eventuell verlorene Verbindungen mit gelöscht werden (kaskadierendes Löschen)
oder das Ändern/Löschen beim Auftreten offener Verbindungen unterbunden werden.
Weiter ist zu klären was mit Konten oder Prädikaten geschieht, die nirgends mehr angebunden sind (Garbage Collection).
Abfragesprache
Die Abfragesprache sollte auf keine Fall wie SQL auf Mengen basieren,sondern auf rekursivem Durchlaufen des Netzes von einem Anker ausgehend.
Statt einer Abfragesprache ist auch einfach ein Satz von Funktionen,
der aus einer beliebigen Programmiersprache über eine Library aufgerufen werden kann.
Da in einer Applikation mehrere Netze existieren könnten, muß das gewünschte Netz gezielt ansprechbar sein.
Alle Operationen die in einem Baum möglich sind,
wie Tiefensuche, Breitensuche, Backtracking, Erkennen rekursiver Verknüpfungen usw. sollten möglich sein.
Beispiel:
for( Netzname , Ankername ) // Durchlaufen aller Ankerlelemente eines bestimmten Ankers
for( Netzname , Ankername , Bedingung ) // Durchlaufen aller Ankerlelemente eines bestimmten Ankers, die der Bedingung entsprechen
for( Netzname , Ankername , Bedingung , for( ... ) ) // rekursives Durchlaufen aller Ankerlelemente eines bestimmten Ankers, die der Bedingung entsprechen, Achtung: Die innere for-Klausel muß später aufgelöst werden (Codeblock, Funktionspointer, Listener usw.)
Die durchlaufenen Elemente kann man:
Löschen
Ändern
Summieren, Minimum, Maximum, Durchschnitt usw.
Eine Vorgehensweise wie in Prolog ist zur Abfrage auch denkbar:
? | Prädikat | Knoten
Zurückgeliefert werden alle Aussagen, die Bedingung erfüllen. Durch Schachtelung der Abfragen sind komplexe Operationen möglich.
Zum Adressieren der einzelnen Knoten und Prädikate sollte ein Pointer existieren.
Intern kann dafür den Element-Key (siehe Implementationsvorschlag) verwenden.
Pointer kann man als Parameter weitergeben, Listen hinzufügen oder auf dem Stack speichern, um das entsprechende Element später wieder anzusprechen.
Jedes Element kann durch einen Pfad beschrieben werden.
{ Netzname:Ankername: [ Prädikat , Knoten ] } // [ Prädikat , Knoten ] kann beliebig oft, aber mindestens einmal auftreten
Durch das Offenlassen oder über eine Bedingung ausgewählte Pfadelemente kann man eine Abfrage zum Durchlaufen aller passenden Elemente realisieren.
Locking, Transaktionen

Eigentlich erfolgt hier schon ein gewisser Vorgriff auf das Implementationskonzept.
Um den Datenbankkern wird eine Schale (Wrapper) gelegt, der die parallelen Anfragen entsprechend dem Transaktionslevel serialisiert, Locks bzw. Semaphore verwaltet und Rollbackpuffer verwaltet.
Kompliziert ist die Festlegung des gelockten Elements/Views, da das gleiche Element über verschiedene Anker erreichbar ist.
Hier muß mit Kombinationen aus Pointern, Pfaden und Views gearbeitet werden.
Implementationskonzept
Die Implementation könnte auf Basis einer relationalen Datenbank erfolgen.Benötigt werden zwei Tabellen, eine für die Elemente und eine für die Verknüpfungen.
| Table: Elemente | |||
|---|---|---|---|
| Ident (Primary Key, Index) | IS_ANKER (BOOL) | IS_KNOTEN (BOOL) | Name, Wert und Atribute (BLOB-Feld) |
| 000000001 | TRUE | TRUE | Ort |
| 000000002 | TRUE | TRUE | Person |
| 000000003 | FALSE | FALSE | wohnt in (Ort) |
| 000000004 | FALSE | FALSE | wohnt in (PLZ) |
| 000000005 | FALSE | FALSE | wohnt in (Strasse) |
| 000000006 | FALSE | FALSE | Telefon |
| 000000007 | FALSE | FALSE | Fax |
| 000000008 | FALSE | FALSE | mobil |
| 000000009 | FALSE | FALSE | |
| 000000010 | FALSE | TRUE | String:Heiner Kücker |
| 000000011 | FALSE | TRUE | String:Hünxe |
| 000000012 | FALSE | TRUE | String:46569 |
| 000000013 | FALSE | TRUE | String:Am Ringwall 16 |
| 000000014 | FALSE | TRUE | String:02858/83334 |
| 000000015 | FALSE | TRUE | String:02858/837434 |
| 000000016 | FALSE | TRUE | String:0163/4281533 |
| 000000017 | FALSE | TRUE | String:Mail@HeinerKuecker.de |
| Table: Links | ||
|---|---|---|
| Subject (Key, Index) | Predicat (Key, Index) | Object (Key, Index) |
| 000000001 | 000000000 | 000000011 |
| 000000002 | 000000000 | 000000010 |
| 000000010 | 000000003 | 000000011 |
| 000000010 | 000000004 | 000000012 |
| 000000010 | 000000005 | 000000013 |
| 000000010 | 000000006 | 000000014 |
| 000000010 | 000000007 | 000000015 |
| 000000010 | 000000008 | 000000016 |
| 000000010 | 000000009 | 000000017 |
Die Key-Nummer 000000000 stellt das implizite Prädikat ist dar.
Vor- und Nachteile
Vorteilhaft ist sicher die flexible Struktur des semantischen Netzes.Diese erfordert beim Anlegen neuer Prädikate viel Disziplin, um schon vorhandene Strukturen nicht nochmals redundant anzulegen.
Nachteilig ist die komplizierte Sperrung.
Zum Speicherbedarf ist zu betrachten, daß für die Referenzen zusätzlicher Speicher benötigt wird, aber
andererseits Speicherplatz für nur selten besetzte Felder, feste Feldlängen und eventuell für Indizes gespart wird.
Ebenso ambivalent ist die Betrachtung der Performance:
Die Referenzierung benötigt mehr Zeit als feste Feldstrukturen, andererseits werden
eventuell Indexaktualisierungen und das Bewegen nicht benötigter Daten gespart.
Bei komplexen Abfragen kann sich das Tuningproblem durch das andere Herangehen erledigen
oder anders stellen, da statt Mengen-Operationen rekursives Durchlaufen des Netzes erfolgt.
Ein Beispiel dafür sind SQL-Joins.
Siehe hierzu auch
Kognitions-Maschine für ein Semantisches Netz